iOS 13から画像から顔認識やバーコード、テキスト認識する Vision.framework が実装された。本記事では VNRecognizeTextRequest を使って画像からテキスト(String)を抽出する方法を紹介する。このクラスでは Convert Image to String をおこなう。
よく似たクラス名の VNDetectTextRectanglesRequest はテキスト領域の矩形情報を得るために使用する。これはOCRに掛ける前段階で使うと良さそうだ。VNDetectTextRectanglesRequest ではテキストを抽出できないので注意したい。
VNRecognizeTextRequest がサポートしている言語を調べる
VNRecognizeTextRequest がサポートしている言語を調べる。
let recognizeTextRequest = VNRecognizeTextRequest() let languages = try! recognizeTextRequest.supportedRecognitionLanguages() print("\(languages)")
iOS 15.4時点ではサポートされている言語は以下の通りである。日本語には対応していない。
["en-US", "fr-FR", "it-IT", "de-DE", "es-ES", "pt-BR", "zh-Hans", "zh-Hant"]
中国語が含まれているなら日本語にも対応してほしいけれど、単純に言語話者の数が多い順にAppleは対応していっているのかもしれない。2世代先のiOS 17くらいでは対応しているのかもしれない。
2022年現在、画像から日本語のテキストを得たいのであれば、Googleの ML Kit on iOS を併用した方が良いかもしれない。本ブログでも後日紹介したい。
VNRecognizeTextRequestを使って画像からテキストを取得する
表題の通り VNRecognizeTextRequest を使って画像からテキストを取得する。対応言語に日本語が含まれていないため、ここでは英語版の「リングフィット アドベンチャー -Switch」のトレーニング結果画像を利用する。
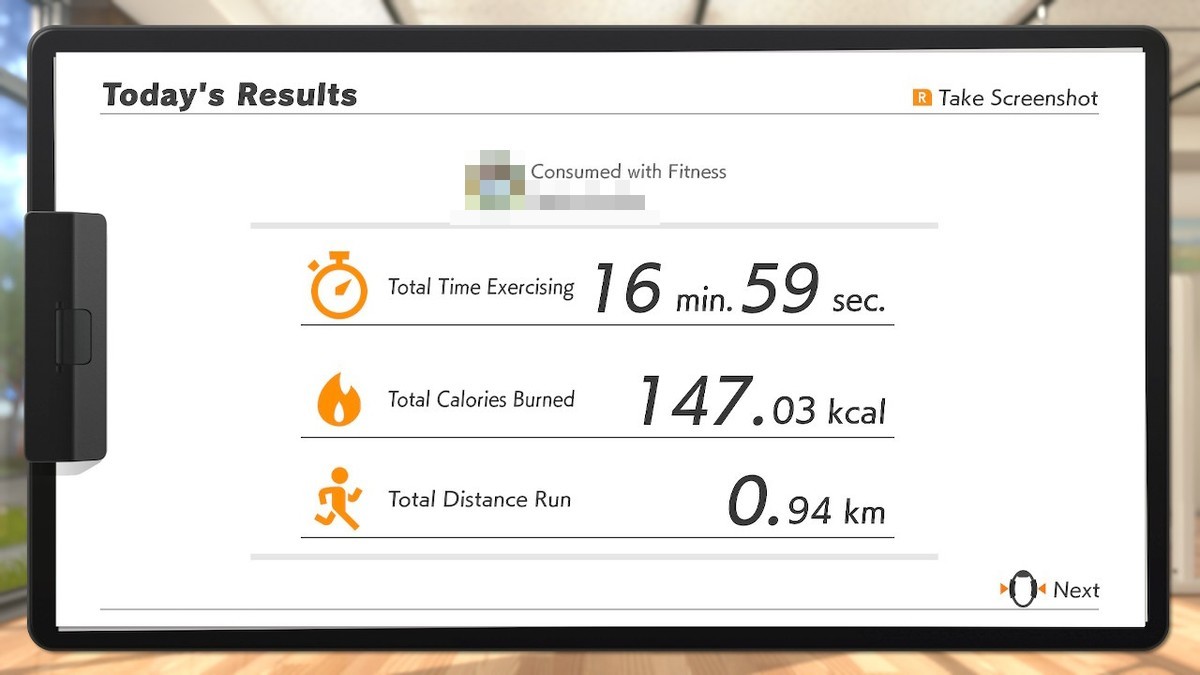
// 解析対象であるターゲット画像を取得する guard let input = UIImage(named: "sample_summary_en")?.cgImage else { return } // テキスト解析後に実行される (非同期処理/あとで呼ばれる) let request = VNRecognizeTextRequest { (request, error) in if let results = request.results as? [VNRecognizedTextObservation] { let strings = results.compactMap { observation in observation.topCandidates(1).first?.string } // 得られたテキストを出力する print(strings) } } // テキスト解析を開始する let handler = VNImageRequestHandler(cgImage: input, options: [:]) DispatchQueue.global(qos: .userInteractive).async { do { try handler.perform([request]) } catch { print(error) } }
以下の結果が得られた。
["Today\'s Results", "R Take Screenshot", "Consumed with Fitness", "USER_NAME", "Total Time Exercising", "16 min. 59", "sec.", "Total Calories Burned", "147.03 kcal", "Total Distance Run", "0.94 km", "Next"]
「16 min. 59 sec.」部分が「16 min. 59」と「sec.」に分割されてしまったが、それ以外に問題はなく高精度でテキストを取得できている。
日本語に対応していれば嬉しかったが残念ながらiOS 15現時点では対応していないので、前述の通りGoogleのML Kitを使うのが良いのかもしれない。